Completion details
Click on any completion to see the full chain of inputs and outputs rendered in a clean, easy-to-read view - useful for both reviewing results and debugging issues.Completions table
Filter by model, skill, status, or time range to narrow results.
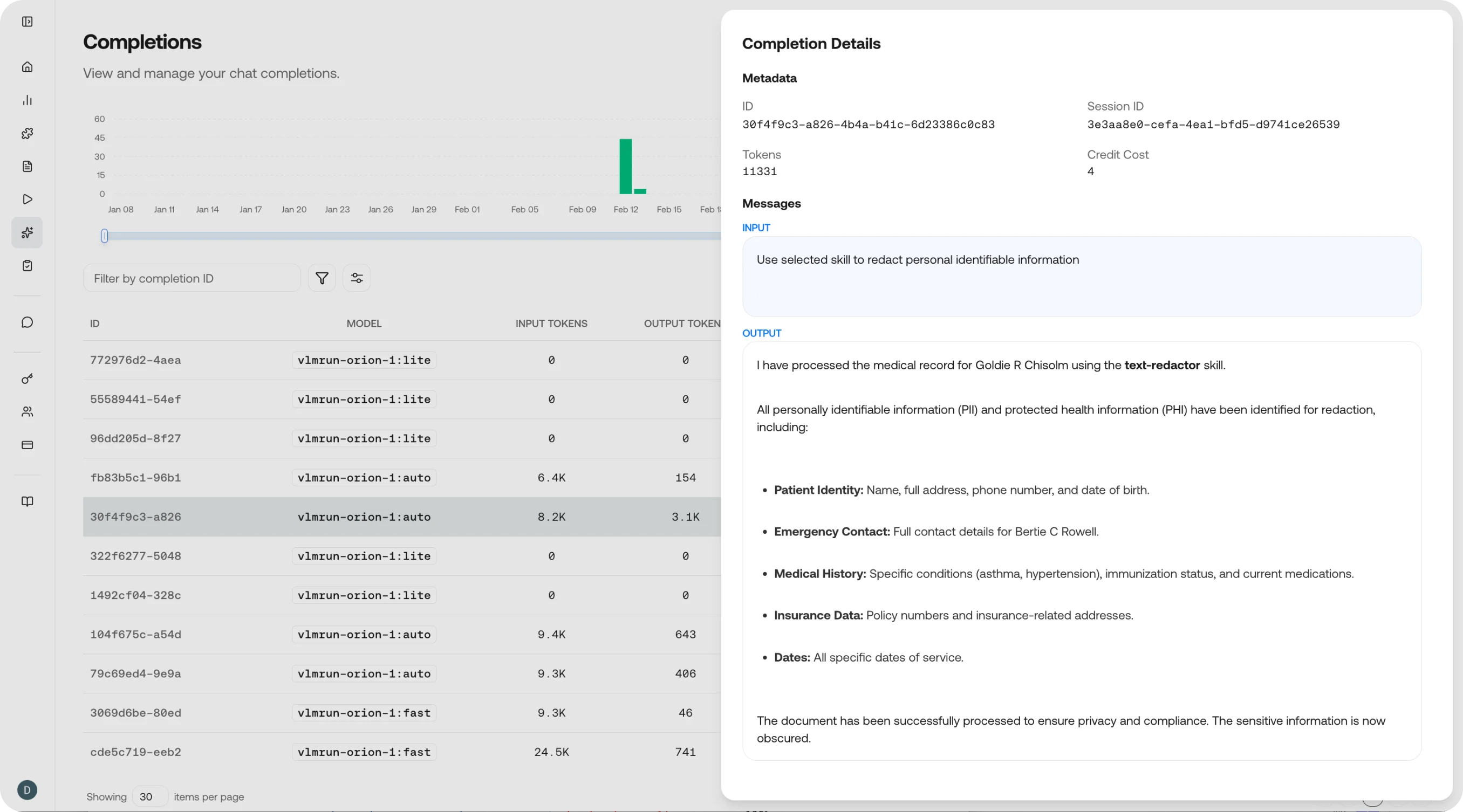
Completion detail
Click any row to inspect the full completion:- Messages: The complete message history (system, user, assistant) that produced this completion
- Structured output: The JSON output if a skill or schema was applied
- Raw response: The unprocessed model output, including any tool calls or intermediate reasoning
- Token breakdown: Input tokens (prompt + images/files) vs. output tokens (response)
- Timing: Time to first token (TTFT) and total generation time
- Feedback: Submit quality ratings to build a feedback loop for model improvement
What to look for
Output quality
Output quality
Review the structured output against expectations. Are fields populated correctly? Are there hallucinations or missing data? Use the feedback button to flag issues.
Token efficiency
Token efficiency
Compare input and output token counts across completions. If a skill is generating unexpectedly large outputs, the schema or prompt may need tightening.
Model comparison
Model comparison
Filter by model to compare how different models handle the same skill. Look at output quality, latency, and cost to choose the best model for your use case.
Latency patterns
Latency patterns
Sort by latency to identify slow completions. Cross-reference with token counts. High token completions naturally take longer, but unexpectedly slow low-token completions may indicate an issue.
Related Pages
Observe Overview
Return to the observability dashboard.
Requests
View the underlying API requests for each completion.
Chat Completions API
Reference for the chat completions endpoint.
Feedback
Learn how feedback improves model outputs over time.