Filtering
Click the date picker in the top right corner to filter the data to any specific timeframe you want to analyze.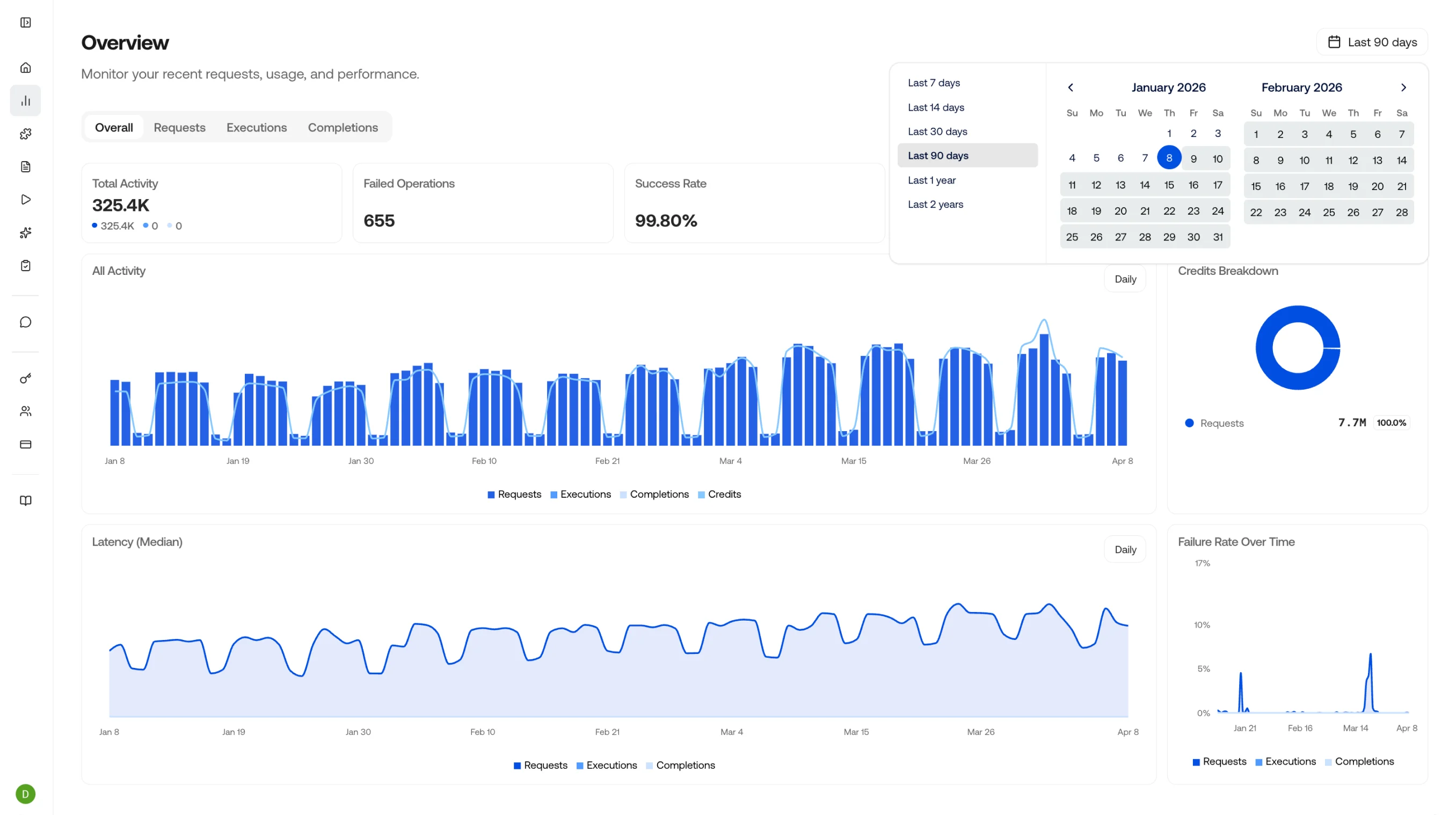
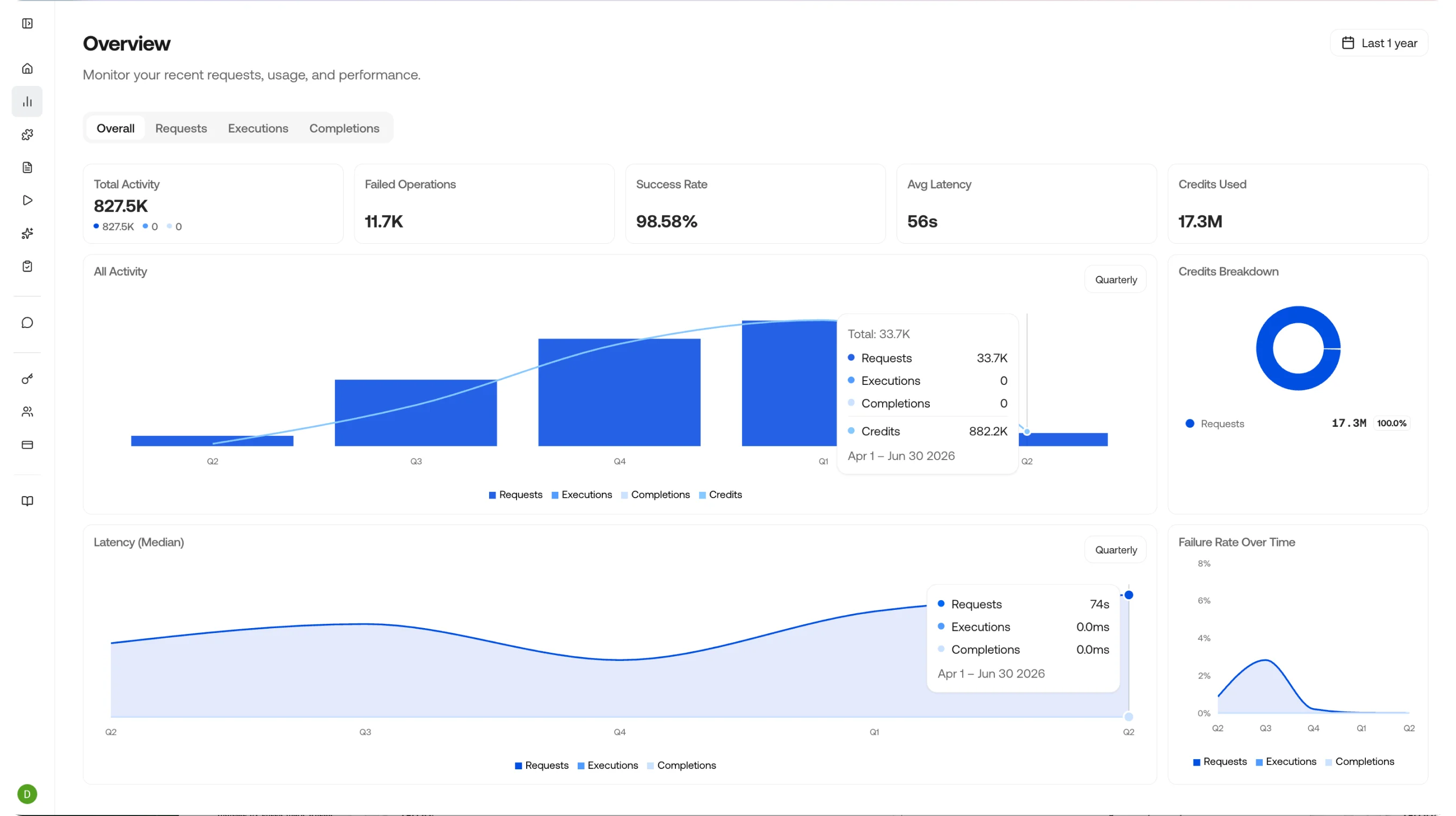
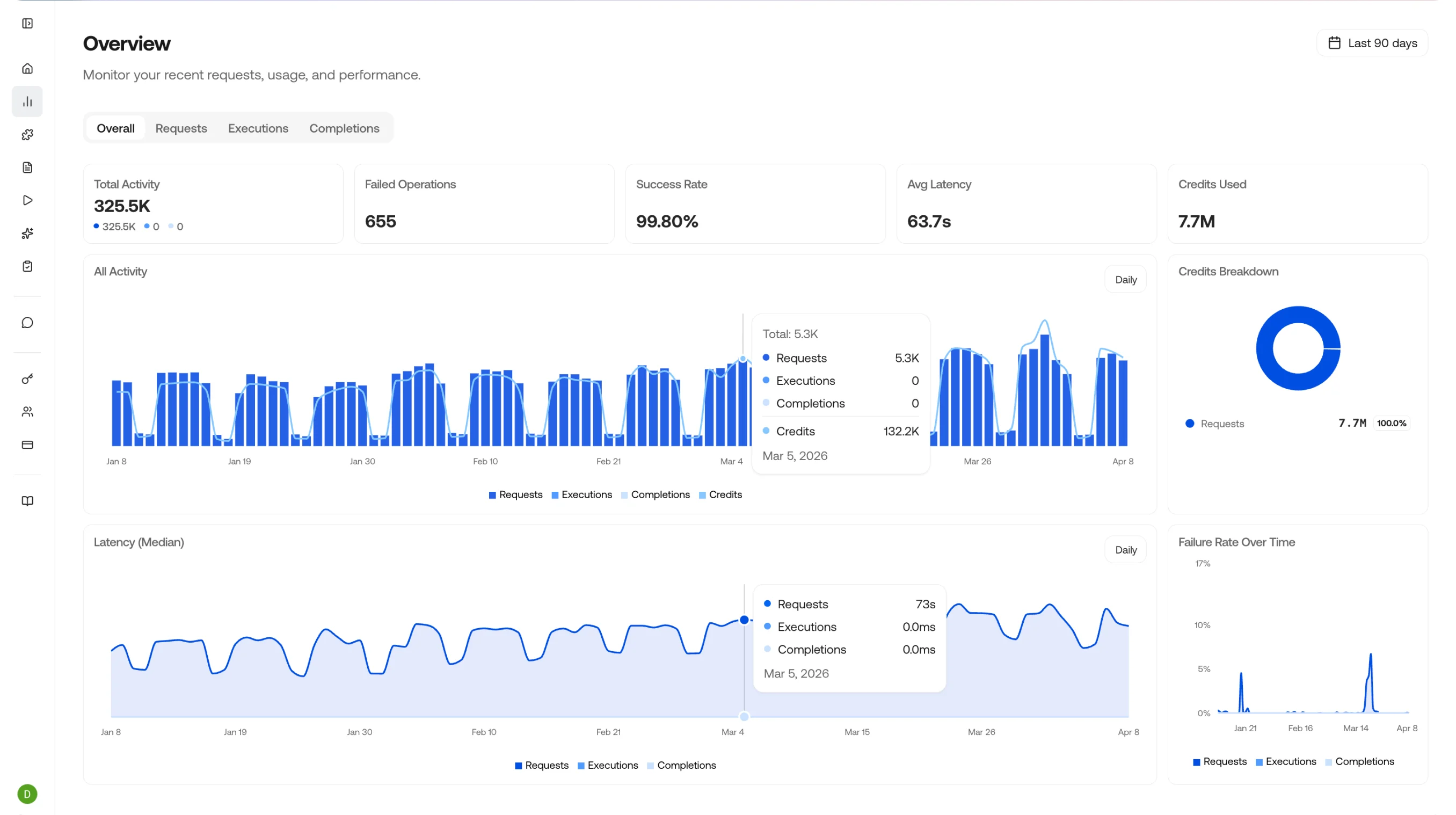
Drill Down
Clicking anywhere on a chart takes you to a drill-down view of that data - an easy way to see the requests, executions, and completions that ran during that time period. Clicking an individual item takes you to its details page.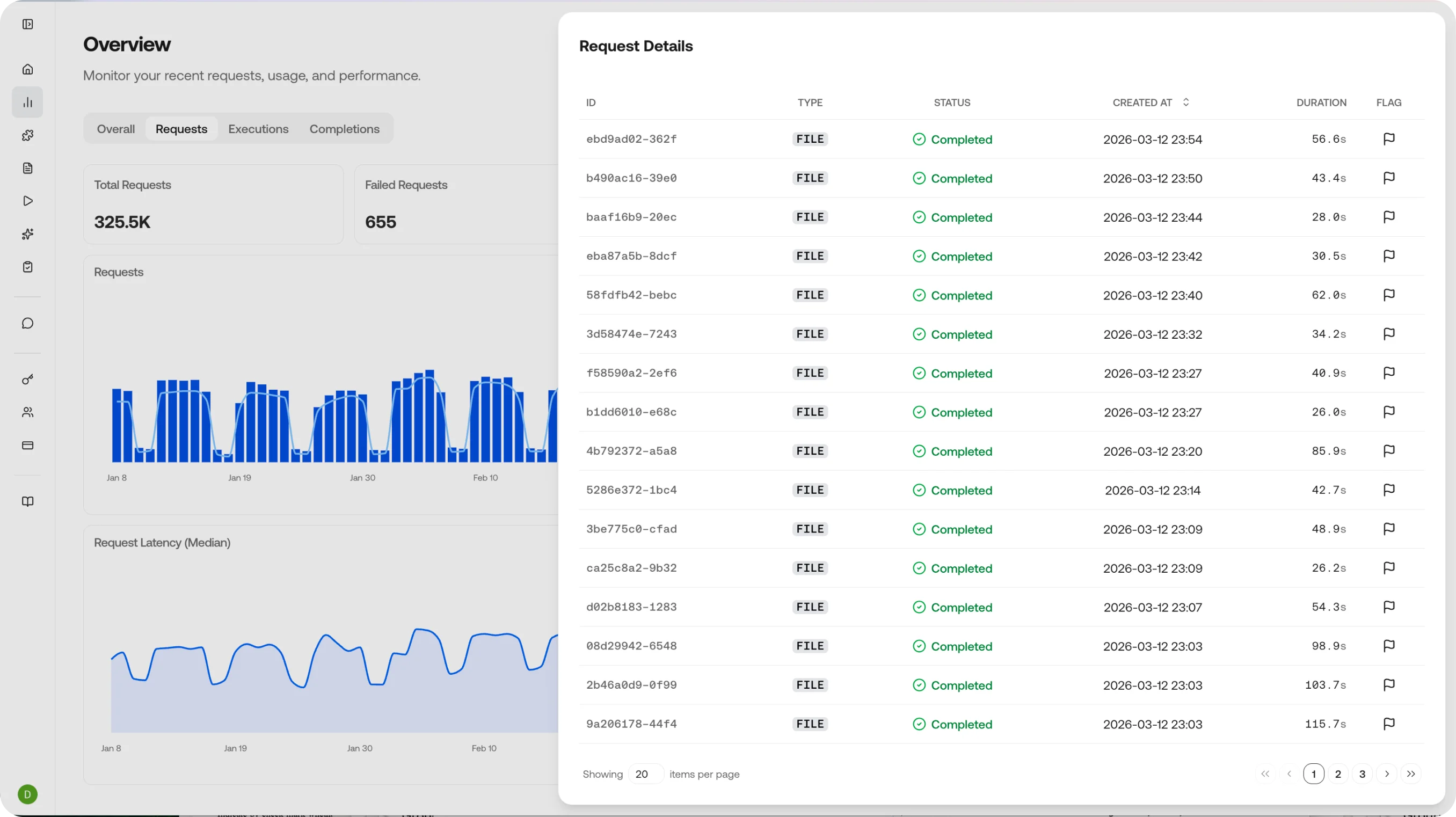
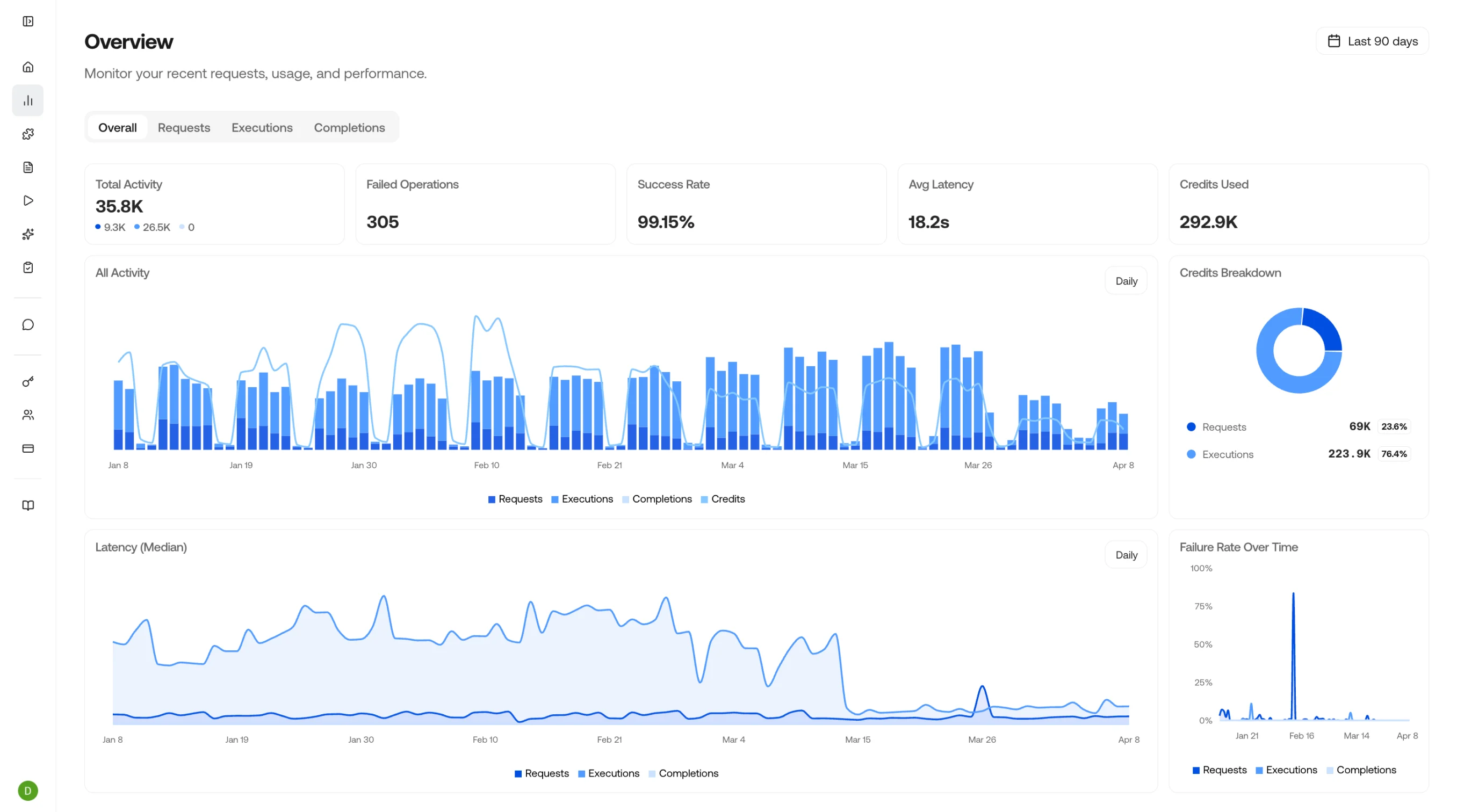
Dashboard Metrics
The overview page shows four key indicators at a glance:Three Views, One Story
Observe is organized into three complementary views that let you drill down from high-level metrics to individual outputs:Requests
Model requests with status, duration, and cost.
Executions
Agent executions with step-by-step traces, artifacts, and timing.
Completions
Chat completions with model, token usage, and the full input and output payload.
Typical Workflows
Debug a failed extraction
Debug a failed extraction
Filter Requests by status
error, find the failing call, and inspect the request payload and error response. Cross-reference with the Completion to see what the model actually returned.Track cost by skill
Track cost by skill
Filter Requests or Completions by skill name to see how many credits each skill is consuming. Identify expensive skills and optimize prompts or schemas to reduce token usage.
Compare model performance
Compare model performance
Review Completions across different models or skill versions to compare output quality, latency, and cost. Use this to decide when to promote a new skill version to production.
Monitor production health
Monitor production health
Check the overview dashboard for success rate drops or latency spikes. Set up alerts via webhooks when metrics cross thresholds.
Related Pages
Requests
View and filter individual API requests.
Executions
Track agent and skill executions.
Completions
Review model completions and outputs.
Evaluations
Run accuracy evaluations from feedback and review field-level metrics.
API Reference
Explore all available API endpoints and responses.