Invoice Parsing Demo
Navigate over to the invoice-parsing playground in our playground to see the invoice parsing in action.
vlm-1 can extract structured data from invoices, along with their visual grounding in PDF or image format. Here’s a step-by-step guide on how to parse an invoice:
Here is a visualization of the parsed invoice along with the visual grounding that vlm-1 can extract from an invoice. Notice that only the specific items requested in the schema are retrieved and visualized, unlike OCR which returns all text in the document with no context:
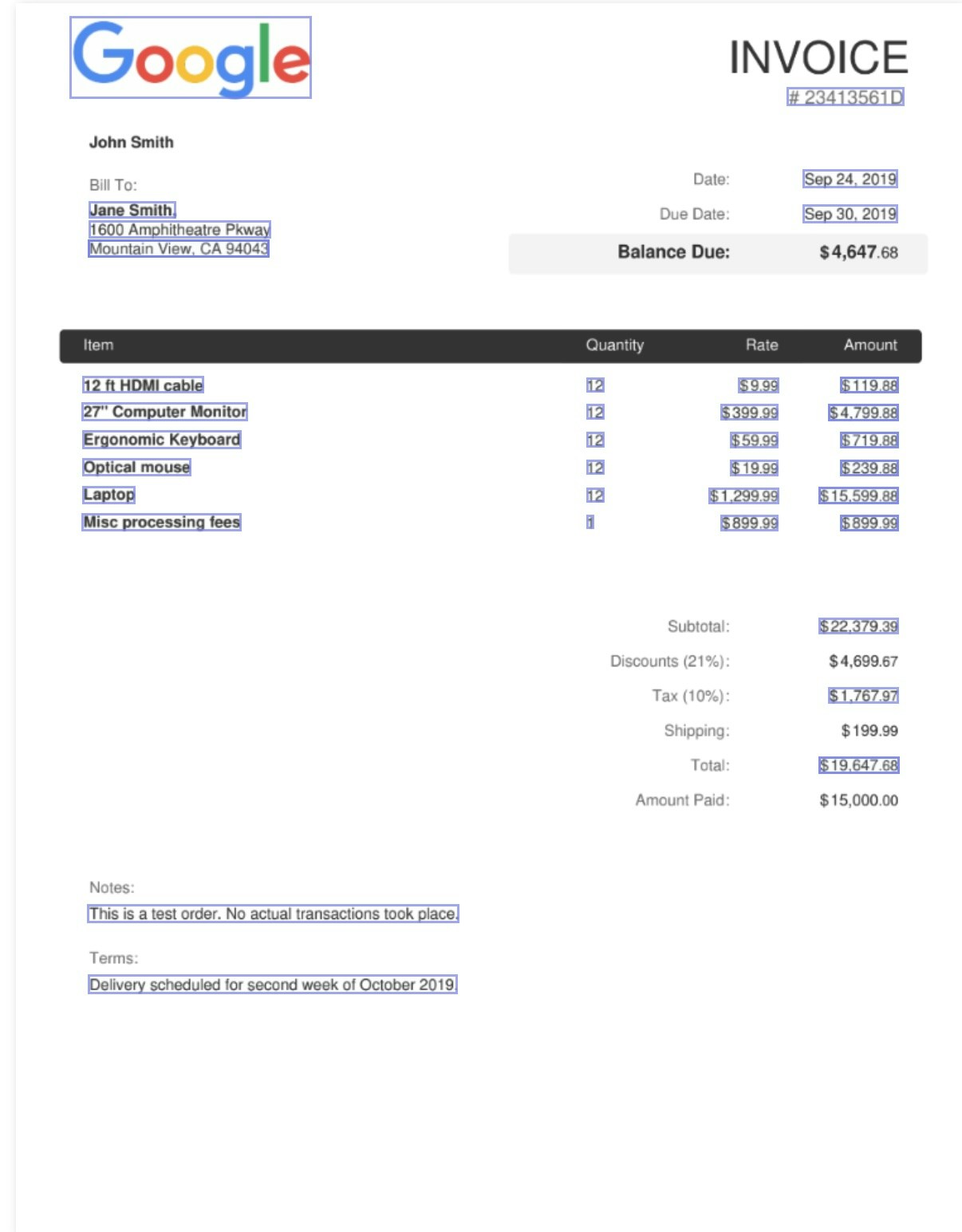
Parsing an invoice with visual grounding enabled
Parsing Invoices in 2 Steps
1
Submit an Invoice Parsing Job
2
Wait for the Job to Complete
You can now wait for the job to complete by calling the
predictions.wait method:High-Accuracy Parsing with Grounding
For higher-quality results, you can enable Visual Grounding to help the model understand the invoice and extract more accurate information. You can do this by setting theconfig=GenerationConfig(grounding=True) parameter when submitting the job (as shown below).