What is VLM Run?
VLM Run is an end-to-end platform for developers to fine-tune, specialize, and operationalize Vision Language Models (VLMs). We aim to make VLM Run the go-to platform for running VLMs with a unified structured output API that’s versatile, powerful and developer-friendly. VLM Run is built on top ofvlm-1, a highly specialized Vision Language Model that allows enterprises to accurately extract JSON from diverse visual sources such as images, documents and presentations - a.k.a. ETL for any visual content. By leveraging vlm-1, enterprises can effortlessly process and index unstructured visual data into their existing JSON databases, transforming raw multi-modal and unstructured information into valuable insights and opportunities.
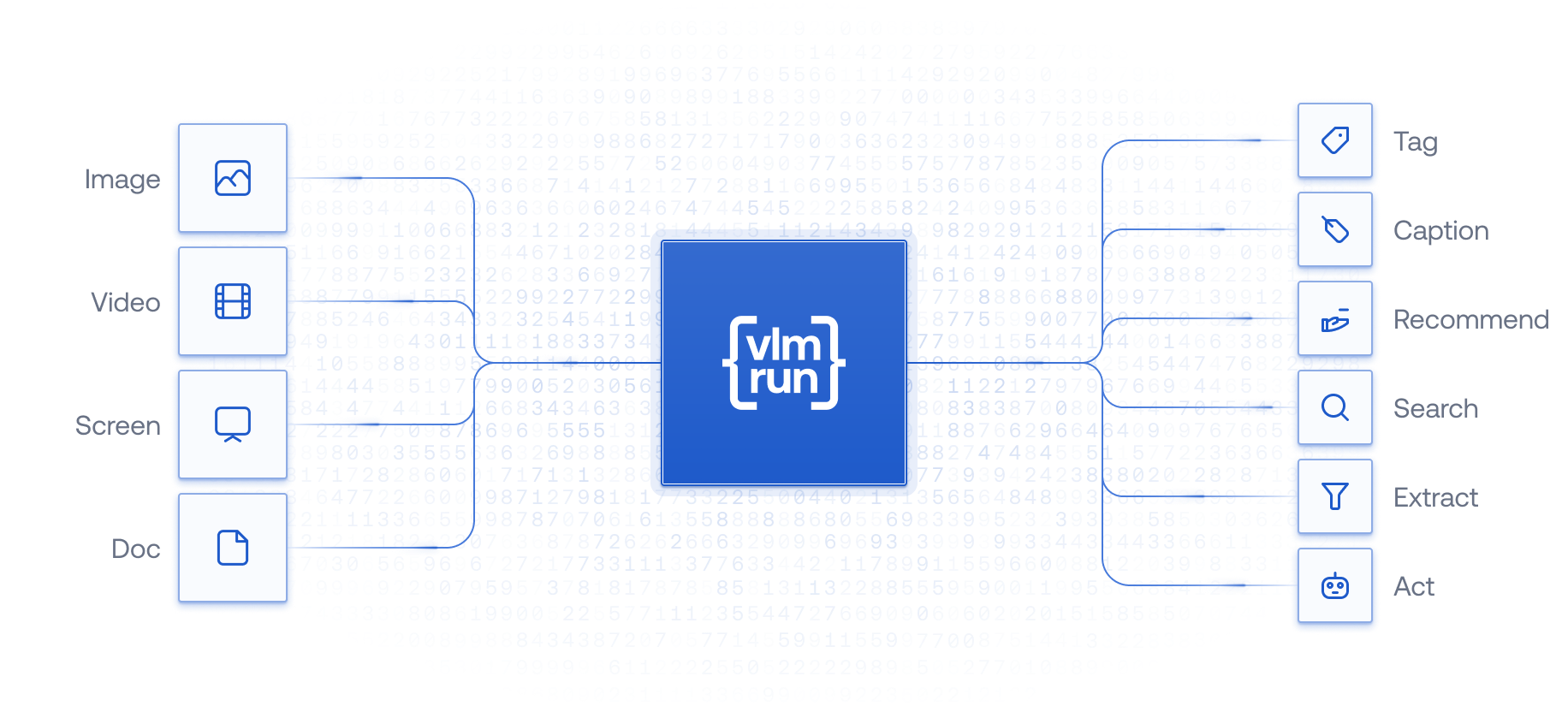
Overview of multi-modal AI understanding with VLM Run.
What makes VLM Run unique?
Here are some key features of VLM Run that set it apart from other foundation models and APIs:Structured Ouptuts
Robustly extract JSON from a variety of visual inputs such as images, videos, and PDFs,
and automate your visual workflows.
Fine-tuning
Fine-tune our models for specific domains and confidently embed vision in your application with enterprise-grade SLAs.
Scalable
Scale your workloads confidently without being rate-limited or worried about your costs spiraling out of control.
Private Deployments
Deploy your custom models on-prem or in a private cloud, and keep your data secure and private.